

به نام خدا
پاکسازی داده
مقدمه
تمامی پروژههای علوم داده، با یک کار شروع میشوند: شما باید دادهی خود را برای استفاده از آن با کامپیوتر آماده کنید.
دادهها باید متناسب با هر برنامهی کامپیوتری، به شکلی مشخص تنظیم شوند. پاکسازی داده (data tidying) ، به عنوان اولین قدم از شروع کار، یکی از مهمترین مهارتهای یک متخصص علوم داده است. این کار مصورسازی، تحلیل و مدل کردن دادهی شما با R را بسیار آسانتر میکند.
در این بخش به روشهای پاکسازی داده میپردازیم.
تمامی پروژههای علوم داده، با یک کار شروع میشوند: شما باید دادهی خود را برای استفاده از آن با کامپیوتر آماده کنید.
دادهها باید متناسب با هر برنامهی کامپیوتری، به شکلی مشخص تنظیم شوند. پاکسازی داده (data tidying) ، به عنوان اولین قدم از شروع کار، یکی از مهمترین مهارتهای یک متخصص علوم داده است. این کار مصورسازی، تحلیل و مدل کردن دادهی شما با R را بسیار آسانتر میکند.
در این بخش به روشهای پاکسازی داده میپردازیم.
نصب پکیجها
در این بخش پکیجهای tidyr و devtools را باید نصب کنید.
در این بخش پکیجهای tidyr و devtools را باید نصب کنید.
In [ ]:
install.packages(c("tidyr", "devtools"))
همچنین از دیتاستهای پکیج DSR در این بخش استفاده شده است که با دستور زیر قابل نصب است:
In [ ]:
devtools::install_github("garrettgman/DSR")
داده تمیز
شما میتوانید دادههای جدولی را به صورتهای مختلفی مرتب کنید. در مثال زیر یک دادهی یکسان به چهار حالت مختلف در دیتاستهای گوناگون مرتب شده است. هر دیتاست ۴ متغیرِ country، year، population، و cases را نمایش میدهد اما هر کدام از دیتاستها این مقادیر را در یک آرایش متفاوت ترتیب میدهند.
شما میتوانید دادههای جدولی را به صورتهای مختلفی مرتب کنید. در مثال زیر یک دادهی یکسان به چهار حالت مختلف در دیتاستهای گوناگون مرتب شده است. هر دیتاست ۴ متغیرِ country، year، population، و cases را نمایش میدهد اما هر کدام از دیتاستها این مقادیر را در یک آرایش متفاوت ترتیب میدهند.
In [1]:
library(DSR)
# Data set one
table1
## Source: local data frame [6 x 4]
##
## country year cases population
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
# Data set two
table2
## Source: local data frame [12 x 4]
##
## country year key value
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583
# Data set three
table3
## Source: local data frame [6 x 3]
##
## country year rate
## 1 Afghanistan 1999 745/19987071
## 2 Afghanistan 2000 2666/20595360
## 3 Brazil 1999 37737/172006362
## 4 Brazil 2000 80488/174504898
## 5 China 1999 212258/1272915272
## 6 China 2000 213766/1280428583
## The last data set is a collection of two tables:
# Data set four
table4 # cases
## Source: local data frame [3 x 3]
##
## country 1999 2000
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766
table5 # population
## Source: local data frame [3 x 3]
##
## country 1999 2000
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583
شاید این طور به نظر برسد که همه دیتاستهای بالا قابل تعویض با یکدیگر هستند چون که یک چیز را نشان میدهند. اما در عمل کار کردن با یکی از این دیتاستها در R بسیار آسانتر از بقیه است.
چرا؟
مجموعه قواعدی که R از آنها پیروی میکند سبب این تفاوت میشود. کار کردن با دادهی شما در R بسیار راحتتر میشود در صورتی که از سه قانون زیر پیروی کنید:
۱. هر متغیر در دیتاست در ستون خودش قرار بگیرد.
۲. هر مشاهده در ردیف خودش قرار بگیرد.
۳. هر مقدار در خانهی خودش در جدول قرار بگیرد.
به این ترتیب جدول۱ (table1) یک دادهی تمیز به حساب میآید.
چرا؟
مجموعه قواعدی که R از آنها پیروی میکند سبب این تفاوت میشود. کار کردن با دادهی شما در R بسیار راحتتر میشود در صورتی که از سه قانون زیر پیروی کنید:
۱. هر متغیر در دیتاست در ستون خودش قرار بگیرد.
۲. هر مشاهده در ردیف خودش قرار بگیرد.
۳. هر مقدار در خانهی خودش در جدول قرار بگیرد.
به این ترتیب جدول۱ (table1) یک دادهی تمیز به حساب میآید.
حال در مثالی ساده تفاوت کار با هر یک از این دیتاستها را نشان میدهیم تا مزیت دادهی تمیز روشن شود.
فرض کنید در این دیتاستها cases مربوط به تعداد مبتلایان به TB در هر کشور، در هر سال باشد. برای محاسبهی «نرخ» موارد مبتلایان به TB در هر کشور، در هر سال (یعنی تعداد افراد به ازای ۱۰۰۰۰ نفر مبتلا به TB)، شما باید چهار عمل زیر را روی داده انجام دهید:
۱. تعداد موارد TB را در هر کشور، در هر سال استخراج کنید.
۲. جمعیت هر کشور در هر سال را به ترتیب بالا استخراج کنید.
۳. موارد را بر جمعیت تقسیم کنید
۴. حاصل را در ۱۰۰۰۰ ضرب کنید.
با استفاده از سینتکس پایهی R، محاسبات شما با هر یک از دیتاستها به صورت زیر میشود:
دیتاست اول
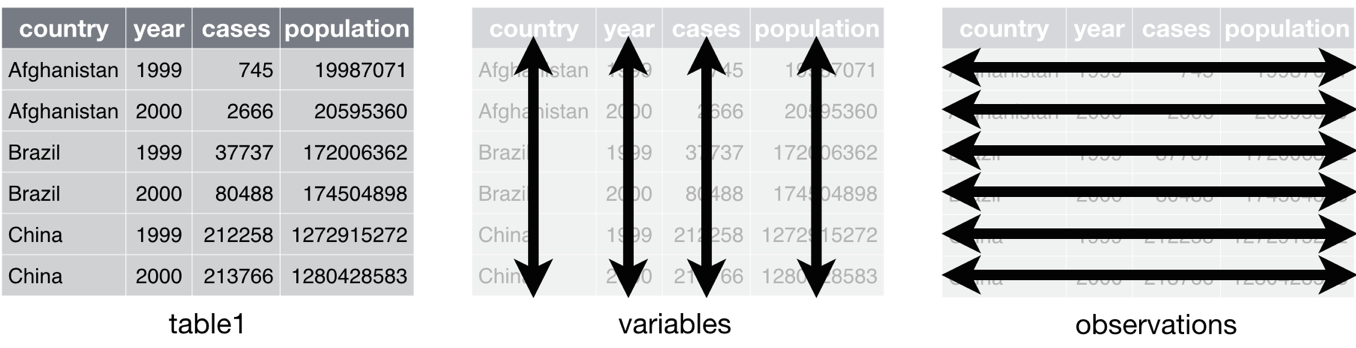
از آنجایی که جدول۱ به روش تمیزی مرتب شده، محاسبات شما به شکل زیر میشود:
فرض کنید در این دیتاستها cases مربوط به تعداد مبتلایان به TB در هر کشور، در هر سال باشد. برای محاسبهی «نرخ» موارد مبتلایان به TB در هر کشور، در هر سال (یعنی تعداد افراد به ازای ۱۰۰۰۰ نفر مبتلا به TB)، شما باید چهار عمل زیر را روی داده انجام دهید:
۱. تعداد موارد TB را در هر کشور، در هر سال استخراج کنید.
۲. جمعیت هر کشور در هر سال را به ترتیب بالا استخراج کنید.
۳. موارد را بر جمعیت تقسیم کنید
۴. حاصل را در ۱۰۰۰۰ ضرب کنید.
با استفاده از سینتکس پایهی R، محاسبات شما با هر یک از دیتاستها به صورت زیر میشود:
دیتاست اول
از آنجایی که جدول۱ به روش تمیزی مرتب شده، محاسبات شما به شکل زیر میشود:
In [2]:
# Data set one
table1$cases / table1$population * 10000
دیتاست دوم
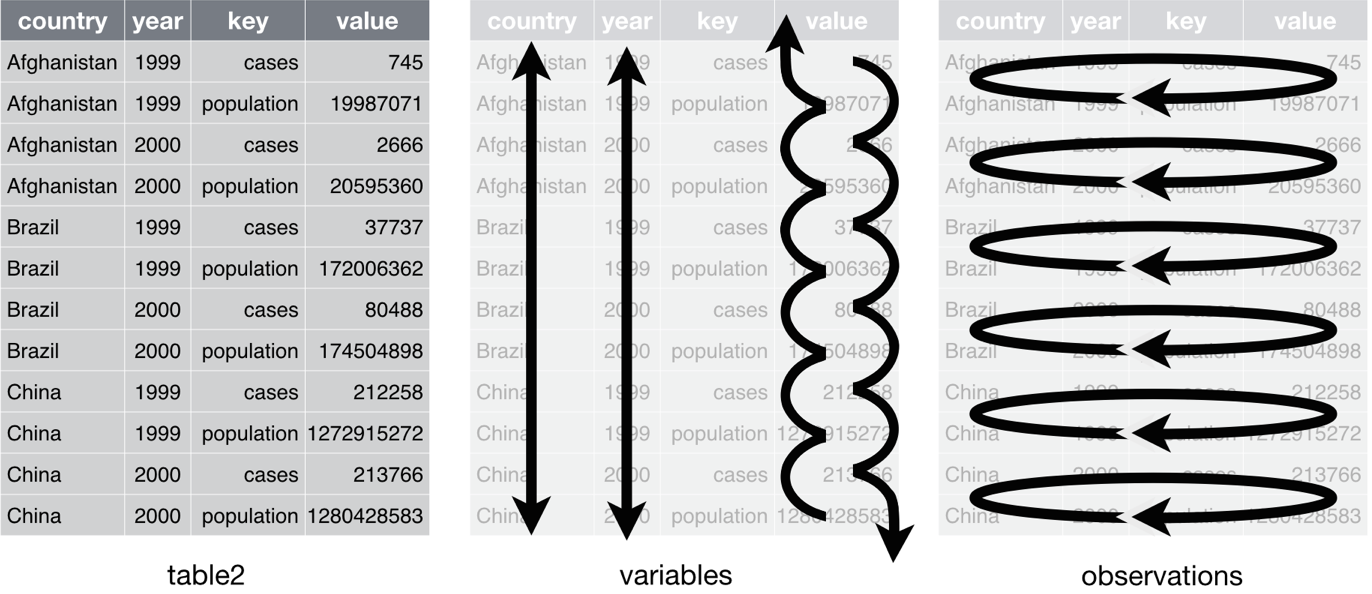
در دیتاست۲ مقادیر جمعیت و موارد مبتلا در یک ستون به صورت مخلوط نگهداری میشوند. بنابراین شما باید این دو مقدار را جدا کنید:
در دیتاست۲ مقادیر جمعیت و موارد مبتلا در یک ستون به صورت مخلوط نگهداری میشوند. بنابراین شما باید این دو مقدار را جدا کنید:
In [3]:
# Data set two
case_rows <- c(1, 3, 5, 7, 9, 11, 13, 15, 17)
pop_rows <- c(2, 4, 6, 8, 10, 12, 14, 16, 18)
table2$value[case_rows] / table2$value[pop_rows] * 10000
دیتاست سوم

دیتاست سوم مقادیر مبتلایان و جمعیت را در یک خانه جدول ترکیب میکند. در نگاه اول شاید این کار به محاسبهی نرخ کمک کند اما در عمل شما باید مقادیر جمعیت را از مقادیر مبتلایان با اعمال ریاضی جدا کنید که برای انجام این کار روشی در سینتکسِ مقدماتی R وجود ندارد.
دیتاست سوم مقادیر مبتلایان و جمعیت را در یک خانه جدول ترکیب میکند. در نگاه اول شاید این کار به محاسبهی نرخ کمک کند اما در عمل شما باید مقادیر جمعیت را از مقادیر مبتلایان با اعمال ریاضی جدا کنید که برای انجام این کار روشی در سینتکسِ مقدماتی R وجود ندارد.
In [4]:
# Data set three
# No basic solution
دیتاست چهارم
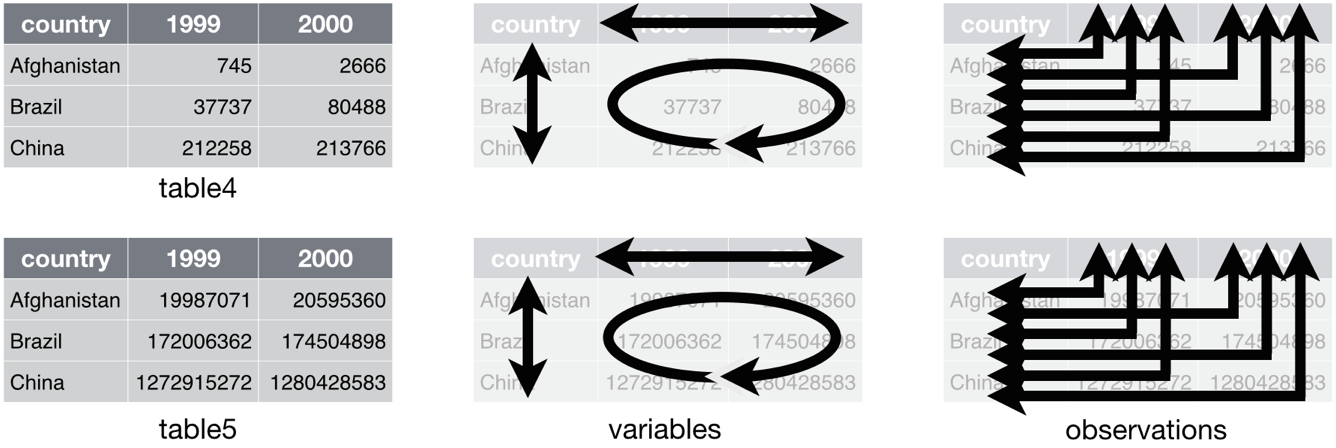
در دیتاست چهارم هر متغیر در فرمتی جداگانه نگهداری میشود: به عنوان یک ستون، مجموعهای از نام ستونها، یک مجموعه از خانههای جدول. در نتیجه شما باید با هر متغیر جداگانه کار کنید. این باعث میشود تعمیم دادن کد نوشته شده برای این دیتاست بسیار مشکل باشد.
علاوه بر اینها سازماندهی داده در دیتاست چهارم بسیار غیربهینه است. دیتاست چهارم مقادیر یک متغیر را در دو جدول متفاوت نگهداری میکند. بنابراین شما برای کار با داده باید از دو جای مختلف اطلاعات را استخراج کنید.
در دیتاست چهارم هر متغیر در فرمتی جداگانه نگهداری میشود: به عنوان یک ستون، مجموعهای از نام ستونها، یک مجموعه از خانههای جدول. در نتیجه شما باید با هر متغیر جداگانه کار کنید. این باعث میشود تعمیم دادن کد نوشته شده برای این دیتاست بسیار مشکل باشد.
علاوه بر اینها سازماندهی داده در دیتاست چهارم بسیار غیربهینه است. دیتاست چهارم مقادیر یک متغیر را در دو جدول متفاوت نگهداری میکند. بنابراین شما برای کار با داده باید از دو جای مختلف اطلاعات را استخراج کنید.
In [5]:
# Data set four
cases <- c(table4$1999, table4$2000, table4$2001)
population <- c(table5$1999, table5$2000, table5$2001)
cases / population * 10000
همانطور که دیدیم کار با دیتاست اول بسیار آسانتر است و برای کار با بقیهی دیتاستها شما باید مراحل بیشتری را طی کنید و این باعث میشود کد شما سختتر نوشته شود، سختتر درک شود، و سختتر عیبیابی شود.
توابع spread() و gather()
شما میتوانید دادههای جدولی را به صورتهای مختلفی مرتب کنید. در مثال زیر یک دادهی یکسان به چهار حالت مختلف درپکیج tidyr برای مرتب کردن داده طراحی شده است. این پکیج چهار تابع دارد که با حفظ مقادیر و روابط، آرایش مجموعه دادههای جدولی را تغییر میدهند.
دو تا از مهمترین توابع موجود در tidyr، توابعِ gather() و spread() هستند. هر دوی اینها بر اساس ایدهی زوج کلید-مقدار (key-value pair) هستند.
زوجهای کلید-مقدار
یک زوج کلید-مقدار راهی ساده برای ثبت اطلاعات است. هر زوج از دو بخش تشکیل شده است: یک «کلید» که نشان میدهد که چه نوع دادهای را توصیف میکند، و یک «مقدار» که خود داده است.
به عنوان مثال ( Password: 0123456789 ) یک زوج کلید-مقدار است که 0123456789 مقداری است که به کلیدِ Password مرتبط شده است.
در دادهی تمیز، هر خانهی جدول، یک مقدار را نگهداری میکند و هر نامِ ستون، یک کلید است.
اما در دادههای غیرتمیز لزوما اینطور نیست. جدول۲ را در نظر بگیرید:
شما میتوانید دادههای جدولی را به صورتهای مختلفی مرتب کنید. در مثال زیر یک دادهی یکسان به چهار حالت مختلف درپکیج tidyr برای مرتب کردن داده طراحی شده است. این پکیج چهار تابع دارد که با حفظ مقادیر و روابط، آرایش مجموعه دادههای جدولی را تغییر میدهند.
دو تا از مهمترین توابع موجود در tidyr، توابعِ gather() و spread() هستند. هر دوی اینها بر اساس ایدهی زوج کلید-مقدار (key-value pair) هستند.
زوجهای کلید-مقدار
یک زوج کلید-مقدار راهی ساده برای ثبت اطلاعات است. هر زوج از دو بخش تشکیل شده است: یک «کلید» که نشان میدهد که چه نوع دادهای را توصیف میکند، و یک «مقدار» که خود داده است.
به عنوان مثال ( Password: 0123456789 ) یک زوج کلید-مقدار است که 0123456789 مقداری است که به کلیدِ Password مرتبط شده است.
در دادهی تمیز، هر خانهی جدول، یک مقدار را نگهداری میکند و هر نامِ ستون، یک کلید است.
اما در دادههای غیرتمیز لزوما اینطور نیست. جدول۲ را در نظر بگیرید:
In [6]:
table2
## Source: local data frame [12 x 4]
##
## country year key value
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583
در جدول۲، ستونِ key، فقط کلیدها را نگهداری میکند و ستونِ value مقادیر مرتبط با هر کلید را دارد.
شما میتوانید از spread() برای تمیز کردنِ این آرایش استفاده کنید.
شما میتوانید از spread() برای تمیز کردنِ این آرایش استفاده کنید.
spread()
تابع spread() یک زوج از ستونهای کلید:مقدار را به مجموعهای از ستونهای تمیز تبدیل میکند.
برای استفاده از این تابع، نام دیتافریم را به عنوان ورودی به آن بدهید، سپس نام ستونِ کلید در دیتافریم، و بعد نام ستونِ مقدار.
تابع spread() یک زوج از ستونهای کلید:مقدار را به مجموعهای از ستونهای تمیز تبدیل میکند.
برای استفاده از این تابع، نام دیتافریم را به عنوان ورودی به آن بدهید، سپس نام ستونِ کلید در دیتافریم، و بعد نام ستونِ مقدار.
In [8]:
table2
## Source: local data frame [12 x 4]
##
## country year key value
## 1 Afghanistan 1999 cases 745
## 2 Afghanistan 1999 population 19987071
## 3 Afghanistan 2000 cases 2666
## 4 Afghanistan 2000 population 20595360
## 5 Brazil 1999 cases 37737
## 6 Brazil 1999 population 172006362
## 7 Brazil 2000 cases 80488
## 8 Brazil 2000 population 174504898
## 9 China 1999 cases 212258
## 10 China 1999 population 1272915272
## 11 China 2000 cases 213766
## 12 China 2000 population 1280428583
library(tidyr)
spread(table2, key, value)
## Source: local data frame [6 x 4]
##
## country year cases population
## 1 Afghanistan 1999 745 19987071
## 2 Afghanistan 2000 2666 20595360
## 3 Brazil 1999 37737 172006362
## 4 Brazil 2000 80488 174504898
## 5 China 1999 212258 1272915272
## 6 China 2000 213766 1280428583
تابع spread() یک رونوشت از دیتاست شما را برمیگرداند که ستونهای کلید و مقدار آن حذف شدهاند. به جای آنها، spread() یک ستون جدید به ازای هر مقدار یکتای ستونِ کلید ایجاد میکند که این مقادیر یکتا، نام ستونهای جدید هستند. تابع spread() خانههای ستونِ سابقِ مقدار را در خانههای ستونهای جدید پخش میکند.

این تابع علاوه بر داده، کلید، و مقدار، سه آرگومان اختیاری دیگر نیز به عنوان ورودی میپذیرد:
- fill: اگر ساختارِ تمیز ترکیبهایی از متغیرها را ایجاد کند که در دیتاست اولیه وجود نداشتهاند، spread() در خانههای جدید NA (علامت دادهی ناپیدا در R) میگذارد. شما میتوانید این عمل را با ورودی دادنِ مقداری جایگزین به fill تغییر دهید.
- convert: در صورتی که یک ستونِ مقدار، شامل انواع مختلفی از داده باشد، این عناصر به یک نوع ذخیره میشوند (معمولا به صورت رشتهای از کاراکترها). اگر شما قرار دهید convert=TRUE، تابع spread() روی هر ستونِ جدید type.convert() را اجرا میکند، که رشتهها را به اعداد، علائم منطقی، و … تبدیل میکند.
- drop: این آرگومان چگونگی رفتارِ spread() با فاکتورها را تعیین میکند. در صورتی که قرار دهید drop=FALSE، تابع spread() سطوحی از فاکتورها را که در ستونِ کلید ظاهر نشدهاند، نگه میدارد و ترکیبهای ناپیدا را با مقدارِ fill پر میکند.
gather()
این تابع کارِ برعکسِ spread() را انجام میدهد. gather() مجموعهای از نام ستونها را میگیرد و آنها را در یک ستونِ «کلید» قرار میدهد. همچنین خانههای آن ستونها را جمعاوری کرده و در یک ستونِ مقدار قرار میدهد.
شما میتوانید از gather() برای تمیز کردنِ جدول۴ استفاده کنید.
این تابع کارِ برعکسِ spread() را انجام میدهد. gather() مجموعهای از نام ستونها را میگیرد و آنها را در یک ستونِ «کلید» قرار میدهد. همچنین خانههای آن ستونها را جمعاوری کرده و در یک ستونِ مقدار قرار میدهد.
شما میتوانید از gather() برای تمیز کردنِ جدول۴ استفاده کنید.
In [9]:
table4 # cases
## Source: local data frame [3 x 3]
##
## country 1999 2000
## 1 Afghanistan 745 2666
## 2 Brazil 37737 80488
## 3 China 212258 213766
برای استفاده از gather()، نام دیتافریم را به عنوان ورودی به آن بدهید، سپس یک رشته کاراکتر برای نامِ ستونِ «کلید»ی که میسازد، و یک رشته کاراکتر برای نامِ ستون مقداری که میسازد. در نهایت مشخص کنید که کدام ستونها باید به زوج کلید مقدار بشکنند.
In [10]:
gather(table4, "year", "cases", 2:3)
## Source: local data frame [6 x 3]
##
## country year cases
## 1 Afghanistan 1999 745
## 2 Brazil 1999 37737
## 3 China 1999 212258
## 4 Afghanistan 2000 2666
## 5 Brazil 2000 80488
## 6 China 2000 213766
تابع gather() یک رونوشت از دیتاست شما را برمیگرداند که ستونهای مشخصشده از آن حذف شدهاند. به جای آنها، gather() دو ستون جدید ایجاد میکند: ستونِ «کلید» که نام سابق ستونهای حذفشده را نگه میدارد، و یک ستون مقدار که مقادیر سابق ستونهای حذفشده را نگه میدارد.

به همین ترتیب میتوان جدول۴ را با استفاده از gather() تمیز کرد:
In [11]:
table5 # population
## Source: local data frame [3 x 3]
##
## country 1999 2000
## 1 Afghanistan 19987071 20595360
## 2 Brazil 172006362 174504898
## 3 China 1272915272 1280428583
gather(table5, "year", "population", 2:3)
## Source: local data frame [6 x 3]
##
## country year population
## 1 Afghanistan 1999 19987071
## 2 Brazil 1999 172006362
## 3 China 1999 1272915272
## 4 Afghanistan 2000 20595360
## 5 Brazil 2000 174504898
## 6 China 2000 1280428583
In [ ]: