

به نام خدا
یادگیری ماشین
مقدمه و دادهی مورد استفاده
هدف این متن آموزش اصول کلی یادگیری ماشین و نحوه انجام یک پروژه یادگیری ماشین از ابتدا تا انتهای آن میباشد در این بخش ما از مجموعهی دادهی(Dataset) قیمت خانههای کالیفرنیا (California Housing Prices dataset) از مخزن StatLib استفاده میکنیم. برای مقاصد آموزشی، یک ویژگی دستهای به این مجموعهی داده اضافه کردهایم و چند ویژگی حذف شدهاند.
هدف این متن آموزش اصول کلی یادگیری ماشین و نحوه انجام یک پروژه یادگیری ماشین از ابتدا تا انتهای آن میباشد در این بخش ما از مجموعهی دادهی(Dataset) قیمت خانههای کالیفرنیا (California Housing Prices dataset) از مخزن StatLib استفاده میکنیم. برای مقاصد آموزشی، یک ویژگی دستهای به این مجموعهی داده اضافه کردهایم و چند ویژگی حذف شدهاند.
در مرحلهی اول باید یک مدل از قیمت خانههای کالیفرنیا، با استفاده از این مجموعهی داده، بسازیم. این مجموعهی داده حاوی مقادیرِ جمعیت، میانهی درآمد، میانهی قیمت خانه و … برای هر منطقه از کالیفرنیا است.
مدل شما باید با داده آموزش ببیند و باید بتواند با داشتن تمام مقادیر دیگر، میانهی قیمت خانه در هر منطقه را پیشبینی کند.
مدل شما باید با داده آموزش ببیند و باید بتواند با داشتن تمام مقادیر دیگر، میانهی قیمت خانه در هر منطقه را پیشبینی کند.
نصب و راهاندازی
برای استفاده از کدهای این دفترچه شما نیاز دارید که پایتون 2 یا 3 را روی سیستم خود نصب کرده باشید. همچین از کتابخانه های Numpy و Pandas و Scikit-learn در این پروژه استفاده خواهد شد. این سه کتابخانه اصلیترین کتابخانهها برای کارهای یادگیری ماشین در زبان پایتون میباشند. برای رسم نمودارها نیز از کتابخانه Matplotlib استفاده میشود. برای دنبال کردن بهتر این دفترچه، بهتر است که اصول مقدماتی برنامهنویسی در زبان پایتون را بلد باشید اما نیاز به دانش خاصی در حوزه یادگیری ماشین ندارید زیرا سعی شده است همه چیز به سادهترین شکل توضیح داده شود.
برای استفاده از کدهای این دفترچه شما نیاز دارید که پایتون 2 یا 3 را روی سیستم خود نصب کرده باشید. همچین از کتابخانه های Numpy و Pandas و Scikit-learn در این پروژه استفاده خواهد شد. این سه کتابخانه اصلیترین کتابخانهها برای کارهای یادگیری ماشین در زبان پایتون میباشند. برای رسم نمودارها نیز از کتابخانه Matplotlib استفاده میشود. برای دنبال کردن بهتر این دفترچه، بهتر است که اصول مقدماتی برنامهنویسی در زبان پایتون را بلد باشید اما نیاز به دانش خاصی در حوزه یادگیری ماشین ندارید زیرا سعی شده است همه چیز به سادهترین شکل توضیح داده شود.
در صورتی که از Anaconda استفاده میکنید این کتابخانهها بر روی پایتون شما نصب شدهاند در غیر این صورت با اجرای دستورات زیر میتوانید این کتابخانهها را نصب کنید. که چون در سیستمی که در حال حاضر از آن استفاده میکنیم این کتابخانهها وجود دارد با پیام زیر روبرو شدهایم.
In [1]:
!pip install numpy
!pip install matplotlib
!pip install pandas
!pip install scikit-learn
در تکه کد زیر کتابخانه numpy را اضافه کردهایم و seed تصادفی آن را تنظیم کردهایم.
دقت کنید که مشخص کردن seed در ابتدای کد نقش مهمی در reproducibility نتایج تولید شده توسط کد شما دارد.
تعداد زیادی از الگوریتمهای یادگیری ماشین از مقادیر تصادفی برای مقداردهیِ اولیه استفاده میکنند بنابراین اگر seed را در ابتدای کد مشخص نکرده باشید در هر بار از اجرای کدتان نتیجهی متفاوتی را به دست خواهید آورد.
در ادامه کتابخانه Matplotlib اضافه شده است و حالت آن به inline تغییر کرده است. در صورتی که بخواهید نمودارهایی که رسم میکنید داخل Jupyter Notebook نمایش داده شوند باید این خط را به کد خودتان اضافه کنید. تنظیمات دیگر برای مشخص کردن سایز متنهای داخل نمودار است. برای ذخیرهسازی نمودارها نیز یک تابع نوشته شده است. این تابع یک پارامتر به نام $\tt{tight\_layout}$ دارد. در تصاویر زیر میتوانید فرق نمودارهایی که با اضافه کردن این ویژگی و بدون آن رسم شدهاند را ببینید. استفاده از این ویژگی هنگامی که میخواهید چند نمودار را در قالب یک تصویر نشان دهید، عادت خوبی است!
در ادامه کتابخانه Matplotlib اضافه شده است و حالت آن به inline تغییر کرده است. در صورتی که بخواهید نمودارهایی که رسم میکنید داخل Jupyter Notebook نمایش داده شوند باید این خط را به کد خودتان اضافه کنید. تنظیمات دیگر برای مشخص کردن سایز متنهای داخل نمودار است. برای ذخیرهسازی نمودارها نیز یک تابع نوشته شده است. این تابع یک پارامتر به نام $\tt{tight\_layout}$ دارد. در تصاویر زیر میتوانید فرق نمودارهایی که با اضافه کردن این ویژگی و بدون آن رسم شدهاند را ببینید. استفاده از این ویژگی هنگامی که میخواهید چند نمودار را در قالب یک تصویر نشان دهید، عادت خوبی است!
In [2]:
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Where to save the figures
PROJECT_ROOT_DIR = "./"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "figs/")
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
# Ignore useless warnings (see SciPy issue #5998)
import warnings
warnings.filterwarnings(action="ignore", message="^internal gelsd")
بارگیری (download) دادهها
تکه کد زیر دادهها را از اینترنت بارگیری میکند و آن را در پوشهی dataset در کنار کد شما قرار میدهد و همچنین داده بارگیری شده را از حالت فشرده خارج میکند.
تکه کد زیر دادهها را از اینترنت بارگیری میکند و آن را در پوشهی dataset در کنار کد شما قرار میدهد و همچنین داده بارگیری شده را از حالت فشرده خارج میکند.
In [3]:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = os.path.join(PROJECT_ROOT_DIR, "datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
بار کردن (load) و کار با دادهها
ما از کتابخانه Pandas برای بار کردن دادهها استفاده میکنیم. تکه کد زیر مجموعهی دادهی بارگیری شده را که به صورت یک فایل با پسوند csv میباشد میخواند و و خروجی آن یک شیء از نوع $\texttt{Pandas.DataFrame}$ است. دیتافریم کتابخانه Pandas قابلیتهای زیادی را در اختیار ما قرار میدهد که در ادامه با برخی از آنها آشنا میشویم.
ما از کتابخانه Pandas برای بار کردن دادهها استفاده میکنیم. تکه کد زیر مجموعهی دادهی بارگیری شده را که به صورت یک فایل با پسوند csv میباشد میخواند و و خروجی آن یک شیء از نوع $\texttt{Pandas.DataFrame}$ است. دیتافریم کتابخانه Pandas قابلیتهای زیادی را در اختیار ما قرار میدهد که در ادامه با برخی از آنها آشنا میشویم.
In [4]:
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
پس از فراخوانی تابع، با استفاده از تابع head پنچ سطر اول از جدول دادهها را مشاهده میکنیم.
In [5]:
housing = load_housing_data()
housing.head()
Out[5]:
همچنین با استفاده از تابع info میتوان به اطلاعات کلی از قبیل تعداد سطرها و ستونها و ویژگیهای هر ستون پی برد.
In [6]:
housing.info()
با دانستن نام ستون میتوان فقط آن ستون دلخواه را از کل دادهها انتخاب کرده و به کمک تابع $\tt{value\_counts}$ درباره مقادیر ممکن برای آن و تعداد تکرار هر کدام از آنها اطلاع پیدا کرد.
In [7]:
housing["ocean_proximity"].value_counts()
Out[7]:
با فراخوانی تابع $\tt{describe}$ آمارههای مفیدی مانند میانگین و انحراف معیار و میانه و ... روی ستونهای مختلف محاسبه خواهدشد.
In [8]:
housing.describe()
Out[8]:
هر Dataframe ای تابعی به نام $\tt{hist}$ دارد که با گرفتن پارامترهایی مانند تعداد bin و ... نمودار هیستوگرام هر یک از ستونها را رسم میکند. این نمودا با استفاده از تابع $\tt{save\_fig}$ که در ابتدا تعریف شد، ذخیره میشوند.
In [9]:
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
save_fig("attribute_histogram_plots")
plt.show()

یکی از مهمترین مفاهیم در یادگیری ماشین مفهوم Generalization است.
ما برای آموزش دادن مدل خود از یک مجموعه داده استفاده میکنیم که Train Set ما است.
اما ما برای ارزیابی مدل خود نمیتوانیم از Train Set استفاده کنیم زیرا مدل ما قبلا این دادهها را دیده است و به آن ها برازش شده است.
بنابراین عملکرد مدلی که با Train Set آموزش دیده شده است روی دادههایی که تا به حال آنها را ندیده است با احتمال خوبی بدتر از عملکردش روی Train Set خواهد بود.
به این پدیده که مدل ما عملکرد خوبی روی دادههای آموزش دارد اما روی دادههای جدید عملکرد بدتری دارد بیشبرازش یا Overfitting میگویند.(مثل دانشآموزی که درسهای خود را مفهومی نمیخواند و آنها را حفظ میکند و به هنگام روربرو شدن با مسالهی جدید، ناتوان میشود :دی)
بنابراین اگر ما بخواهیم متوجه شویم که مدل ما روی داده هایی که تا به حال با آن ها روبرو نشده است چه عملکردی دارد باید از قبل یک قسمت از دادههایمان را جدا کرده باشیم و فرآیند آموزش مدل را فقط با باقی دادهها انجام دهیم. بنابراین ما دادههایمان را به دو قسمت Train Set و Test Set تقسیم میکنیم. برای اینکه Test Set نمایانگر داده ای باشد که مدل ما تا به حال با آن روبرو نشده است باید به اصطلاح بعد از جداکردن Test Set آن را در یک گاوصندوق قرار دهیم و تا مشخص نشدن مدل نهایی ارزیابی نهایی را روی این مجموعه انجام ندهیم!
با استفاده از تابع $\tt{train\_test\_split}$ که در کتابخانه sklearn قرار دارد میتوانیم دادههایمان را به دو مجموعه مجزای Train و Test تفکیک کنیم. ورودی $\tt{test\_size}$ در این تابع مشخص میکند که چه کسری از دادهها به عنوان داده تست در نظر گرفته شود. این تابع دادهها را به صورت تصادفی به دو مجموعه Train و Test تقسیم میکند. برای اینکه خروجی تابع در دفعات مختلف اجرا یکسان باقی بماند باید $\tt{random\_state}$ را به عنوان ورودی تابع مشخص کنیم.
بنابراین اگر ما بخواهیم متوجه شویم که مدل ما روی داده هایی که تا به حال با آن ها روبرو نشده است چه عملکردی دارد باید از قبل یک قسمت از دادههایمان را جدا کرده باشیم و فرآیند آموزش مدل را فقط با باقی دادهها انجام دهیم. بنابراین ما دادههایمان را به دو قسمت Train Set و Test Set تقسیم میکنیم. برای اینکه Test Set نمایانگر داده ای باشد که مدل ما تا به حال با آن روبرو نشده است باید به اصطلاح بعد از جداکردن Test Set آن را در یک گاوصندوق قرار دهیم و تا مشخص نشدن مدل نهایی ارزیابی نهایی را روی این مجموعه انجام ندهیم!
با استفاده از تابع $\tt{train\_test\_split}$ که در کتابخانه sklearn قرار دارد میتوانیم دادههایمان را به دو مجموعه مجزای Train و Test تفکیک کنیم. ورودی $\tt{test\_size}$ در این تابع مشخص میکند که چه کسری از دادهها به عنوان داده تست در نظر گرفته شود. این تابع دادهها را به صورت تصادفی به دو مجموعه Train و Test تقسیم میکند. برای اینکه خروجی تابع در دفعات مختلف اجرا یکسان باقی بماند باید $\tt{random\_state}$ را به عنوان ورودی تابع مشخص کنیم.
In [10]:
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
در زیر 5 سطر اول دادههای تست را میبینیم. مشاهده میکنیم که اندیس سطرها دیگر به ترتیب نیست و به صورت تصادفی است.
In [11]:
test_set.head()
Out[11]:
فرض کنید که از دانش پیشین خود میدانیم که ویژگی $\tt{median\_income}$ ویژگی بسیار مهمی برای پیش بینی میانه قیمت خانه ها در هر ناحیه است.
بنابراین میخواهیم که این ویژگی در داده های Train و Test به صورت متعادل تقسیم شده باشد.
In [12]:
housing["median_income"].hist()
Out[12]:

فرض کنید در یک مسئله ویژگی مشخصی که میخواهیم به صورت متعادل بین مجموعه Train و Test تقسیم شود، ویژگی جنسیت افراد باشد.
در این صورت کافی است درصد تعداد مردان و زنان در مجموعههای Train و Test یکسان باشد.
اما ویژگی $\tt{median\_income}$ یک ویژگی با مقادیر پیوسته است. بنابراین برای این که بتوانیم به صورت متعادل این ویژگی را بین مجموعههای Trainو Test تقسیم کنیم ابتدا یک ویژگی گسسته به نام $\tt{income\_cat}$ از روی این ویژگی میسازیم و سپس با استفاده از آن مجموعه Train و Test را درست میکنیم.
ویژگی $\tt{income\_cat}$ مقادیر بین 1 تا 5 را اختیار میکند.
In [13]:
# Divide by 1.5 to limit the number of income categories
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
# Label those above 5 as 5
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
housing["income_cat"].value_counts()
Out[13]:
درصد تکرار هر کدام از این مقادیر در مجموعهی تمام دادهها در زیر آمده است.
In [14]:
housing["income_cat"].value_counts() / len(housing)
Out[14]:
با مشخص کردن ورودی $\tt{stratify}$ در تابع $\tt{train\_test\_split}$ میتوانیم ویژگی ای را مشخص کنیم که به صورت متعادل بین Train و Test تقسیم شوند.
در زیر برای هر دو حالت (تقسیم متعادل و تقسیم معمولی) میتوانیم درصد تکرار هر کدام از مقادیر ۱ تا ۵ را در داده تست مشاهده کنیم. میبینیم که در حالتی که از $\tt{stratify}$ استفاده کرده باشیم
درصد هر یک از ویژگیها در مجموعه Test به درصد هرکدام از ویژگیها در مجموعه دادههای اولیه نزدیکتر است.
In [15]:
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
strat_train_set, strat_test_set = train_test_split(housing, test_size=0.2, random_state=42, stratify=housing['income_cat'])
In [16]:
test_set["income_cat"].value_counts() / len(test_set)
Out[16]:
In [17]:
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
Out[17]:
حال میتوانیم ستون $\tt{income\_cat}$ را که به صورت موقتی به دادهها اضافه کردهایم را حذف کنیم.
In [18]:
strat_train_set.drop("income_cat", axis=1, inplace=True)
strat_test_set.drop("income_cat", axis=1, inplace=True)
مصورسازی دادهها
در این قسمت با رسم نمودارهایی، اطلاعات کلیتری راجع به ساختار دادههایی که داریم به دست میآوریم. از این پس فقط با دادههای Train ای که در قسمت قبل از دادههای اصلی جدا کردهایم کار میکنیم و دیگر به دادههای Test دست نمیزنیم.
در این قسمت با رسم نمودارهایی، اطلاعات کلیتری راجع به ساختار دادههایی که داریم به دست میآوریم. از این پس فقط با دادههای Train ای که در قسمت قبل از دادههای اصلی جدا کردهایم کار میکنیم و دیگر به دادههای Test دست نمیزنیم.
In [19]:
housing = strat_train_set.copy()
با فراخوانی تابع plot روی یک Dataframe میتوانیم یکی از ویژگیها را بر حسب دیگری رسم کنیم.
In [20]:
housing.plot(kind="scatter", x="longitude", y="latitude")
save_fig("bad_visualization_plot")

برای اینکه شهود بهتری از نحوه توزیع دادهها به دست بیاوریم میتوانیم ورودی $\tt{alpha}$ را تنظیم کنیم تا جاهایی که داده های بیشتری وجود دارد پررنگتر رسم شوند و بقیه جاها کمرنگتر. این نمودار نحوه توزیع خانهها را در طول و عرضهای جغرافیایی مختلف نشان میدهد.
In [21]:
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
save_fig("better_visualization_plot")

حال میخواهیم جمعیت ساکن هر منطقه و همچنین میانهی قیمت خانههای هر منطقه را نیز به نموداری که در قسمت قبل رسم کردیم اضافه کنیم.
برای اینکار سایز هرکدام از نقاطی که در نمودار رسم میکنیم را متناسب با ویژگی $\tt{population}$ در نظر میگیریم و رنگ آن را متناسب با $\tt{median\_house\_value}$ در نظر میگیریم.
تکه کد پایین این نمودار را تولید میکند.
In [22]:
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
sharex=False) # s is size and c is color
plt.legend()
save_fig("housing_prices_scatterplot")

حال با اضافه کردن نقشه جغرافیایی کالیفرنیا در کنار نقشه بالا متوجه میشویم که ناحیههایی که به دریا نزدیکتر هستند جمعیت ساکن بیشتری دارند و قیمت آن خانهها نیز بیشتر است.
In [23]:
import matplotlib.image as mpimg
california_img=mpimg.imread(PROJECT_ROOT_DIR + '/figs/california.png')
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar()
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
save_fig("california_housing_prices_plot")
plt.show()

هدف پیشبینی $\tt{median\_house\_value}$ از روی بقیه ویژگیها است. تکه کد پایین همبستگی (correlation) هر کدام از ویژگیها را با این ویژگی مشخص میکند و با استفاده از تابع $\tt{sort}$ آنها را به ترتیب نزولی نمایش میدهد. مشاهده میکنیم که $\tt{median\_income}$ رابطه خطی نسبتا زیادی با $\tt{median\_house\_value}$ دارد.
In [24]:
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
Out[24]:
با تابع $\tt{scatter\_matrix}$ میتوانیم نمودار هر ویژگی بر حسب ویژگی دیگر را رسم کنیم.
نمودارهایی که روی قطر قرار دارند هیستوگرام هریک از ویژگیها است.
In [25]:
# from pandas.tools.plotting import scatter_matrix # For older versions of Pandas
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
save_fig("scatter_matrix_plot")

حال اگر به نمودار $\tt{median\_income}$ بر حسب $\tt{median\_house\_value}$ نگاه کنیم متوجه میشویم که تعداد زیادی از ناحیهها هست که $\tt{median\_income}$ های متفاوتی دارند اما $\tt{median\_house\_value}$
برای آنها مقدار 500000 دارد.
از روی این نمودار متوجه میشویم که احتمالا ستون $\tt{median\_house\_value}$ که در دادهها وجود داشت قبلا از بالا بریده(clip) شده است و مقادیر بیشتر از 500000 را برابر با 500000 قرار داده اند.
In [26]:
housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1)
plt.axis([0, 16, 0, 550000])
save_fig("income_vs_house_value_scatterplot")

احتمالا متوجه شدهاید که ویژگیهای $\tt{total\_rooms}$ و $\tt{population}$ و $\tt{total\_bedrooms}$ برای ناحیههای مختلف قابل مقایسه نیستند زیرا در هر ناحیه تعداد خانههای متفاوتی وجود دارد و هر چه تعداد خانهها بیشتر باشد این مقادیر نیز بیشتر خواهند بود.
به منظور داشتن اطلاعات مفیدتری از این ستونها کد زیر ویژگیهای $\tt{rooms\_per\_household}$ و $\tt{bedrooms\_per\_room}$ و $\tt{population\_per\_household}$ را به Dataframe اضافه میکند.
In [27]:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
حال بعد از اضافه کردن این ویژگیها میتوانیم دوباره همبستگیها را حساب کنیم.
مشاهده میکنیم که ویژگی $\tt{bedrooms\_per\_room}$ که اضافه کردهایم رابطه خطی معکوس نسبتا زیادی با $\tt{median\_house\_value}$ دارد در حالی که $\tt{total\_bedrooms}$ تقریبا هیچ رابطهای خطی با $\tt{median\_house\_value}$ ندارد.
یکی از کارهایی که تاثیر زیادی در کارآیی مدل شما دارد Feature Engineering یا انتخاب کردن و تغییر دادن ویژگیها به گونهای است که برای مدل قابل فهمتر باشند. کاری که پیش از این انجام دادیم نمونهای از آن است.
In [28]:
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
Out[28]:
In [29]:
housing.plot(kind="scatter", x="rooms_per_household", y="median_house_value",
alpha=0.2)
plt.axis([0, 5, 0, 520000])
plt.show()

پس از تغییراتی که صورت گرفت آمارههای کلی درباره ستونهای مختلف را به دست میآوریم.
In [30]:
housing.describe()
Out[30]:
آمادهسازی دادهها برای الگوریتمهای یادگیری ماشین
حال با رسم نمودارهایی اطلاعات کلیتری در مورد ویژگیهایی که داریم به دست میآوریم. در این بخش برچسب دادهها را از دادهها جدا کرده و در متغیر دیگری نگه میداریم و روی بقیه ویژگیها کار میکنیم.
حال با رسم نمودارهایی اطلاعات کلیتری در مورد ویژگیهایی که داریم به دست میآوریم. در این بخش برچسب دادهها را از دادهها جدا کرده و در متغیر دیگری نگه میداریم و روی بقیه ویژگیها کار میکنیم.
In [31]:
housing = strat_train_set.drop("median_house_value", axis=1) # drop labels for training set
housing_labels = strat_train_set["median_house_value"].copy()
بیشتر الگوریتمهای یادگیری ماشین نمیتوانند با ویژگیهایی کار کنند که در بعضی از دادهها جا افتادهاند. از این رو پیش از آن که دادهها به الگوریتم داده شوند، میبایست تغییراتی در آنها صورت گیرد. برای این کار روشهای متعددی وجود دارد که مهمترین آنها در ادامه آمده است. ابتدا تعدادی از دادهها را که ويژگی NaN دارند بدست میآوریم.
In [32]:
sample_incomplete_rows = housing[housing.isnull().any(axis=1)].head()
sample_incomplete_rows
Out[32]:
همان طور که دیده میشود ستون $\tt{total\_bedrooms}$ در مثالهای بالا مقدار NaN دارد. در روش اول میتوان تمام سطرهایی را که در یک یا چند ویژگی دلخواه مقدار مشخص ندارند، حذف کرد. پس از این کار میتوان دید که تمام دادههایی که در ستون $\tt{total\_bedrooms}$ مقدار نامشخص داشتند حذف میشوند.
In [33]:
sample_incomplete_rows.dropna(subset=["total_bedrooms"]) # option 1
Out[33]:
در روش دوم میتوان کل ستون $\tt{total\_bedrooms}$ را از ویژگیهایی که در نظر گرفته میشود حذف کرد. باید توجه داشت که در بعضی موارد این کار میتواند موجب آن شود که ویژگی مهمی به علت مشخص نبودنش برای تعداد اندکی از دادهها حذف شده و فرایند یادگیری را سختتر کند.
In [34]:
sample_incomplete_rows.drop("total_bedrooms", axis=1) # option 2
Out[34]:
روش سوم که بیشتر توصیه میشود آن است که مقادیر گمشده را با استفاده از دادههایی که از آن ویژگی داریم پر کنیم. به عنوان مثال میتوان میانه دادهها را به جای مقادیری که مشخص نیستند قرار داد.
In [35]:
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True) # option 3
sample_incomplete_rows
Out[35]:
اخطار: از آنجا که از ورژن ۰.۲۰ کتابخانه Scikit-Learn به بعد sklearn.preprocessing.Imputer با sklearn.preprocessing.SimpleImupter جایگزین شده است به صورت زیر این کلاس را import میکنیم. در نمونهای که از این کلاس میگیریم مشخص میکنیم که میخواهیم مقادیر گمشده را با استفاده از میانه جایگزین کنیم.
In [36]:
try:
from sklearn.impute import SimpleImputer # Scikit-Learn 0.20+
except ImportError:
from sklearn.preprocessing import Imputer as SimpleImputer
imputer = SimpleImputer(strategy="median")
از آنجا که میانه تنها برای دادههای عددی قابل محاسبه است، یک کپی از دادهها درست میکنیم که داده از نوع متن $\tt{ocean\_proximity}$ را نداشته باشد.
In [37]:
housing_num = housing.drop('ocean_proximity', axis=1)
# alternatively: housing_num = housing.select_dtypes(include=[np.number])
سپس با استفاده از تابع $\tt{fit}$ و دادن مجموعه دادهها به عنوان ورودی، میتوان میانهها را به دست آورد که نتیجه در متغیر $\tt{statistics\underline{}}$ ذخیره شده است.
In [38]:
imputer.fit(housing_num)
Out[38]:
In [39]:
imputer.statistics_
Out[39]:
بررسی میکنیم که مقادیر محاسبه شده در بالا با مقادیری که از محاسبهی مستقیم میانهها به دست میآیند، یکی هستند یا خیر.
In [40]:
housing_num.median().values
Out[40]:
حال با فراخوانی تابع $\tt{transform}$ روی imputerای که آموزش داده شده است، مقادیر گمشده را برای دادهی اولیه جایگزین میکنیم.
In [41]:
X = imputer.transform(housing_num)
از آن جا که نتیجه اجرای این تابع یک آرایه numpy است، آن را به حالت dataframe در میآوریم.
In [42]:
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index = list(housing.index.values))
حال پس از اعمال تغییرات، دادههایی را که مقادیر گمشده داشتند نمایش میدهیم. همان طور که در ادامه میبینید ستون $\tt{total\_bedrooms}$ برای همه آنها با مقدار میانه، جایگزین شده است.
In [43]:
housing_tr.loc[sample_incomplete_rows.index.values]
Out[43]:
In [44]:
imputer.strategy
Out[44]:
In [45]:
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
housing_tr.head()
Out[45]:
در ادامه میخواهیم با دادهی دستهای $\tt{ocean\_proximity}$ کار کنیم. همان طور که پیش از این ذکر شد این ویژگی از نوع متن است و به همین دلیل نمیتوان میانهاش را محاسبه کرد. بیشتر الگوریتمهای یادگیری ماشین با مقادیر عددی کار میکنند پس بهتر است این نوع ویژگیها را به عدد تبدیل کرد.
In [46]:
housing_cat = housing[['ocean_proximity']]
housing_cat.head(10)
Out[46]:
اخطار: برای عددی کردن ویژگیهای متنیِ دستهای میتوان از کلاسهای $\tt{LabelEncoder}$ و یا تابع $\tt{Series.factorize()}$ مربوط به کتابخانه Pandas استفاده کرد. اما کلاس $\tt{OrdinalEncoder}$ که در ورژن ۰.۲۰ Scikit-Learn ارائه شده است به علت آنکه با ويژگیهای ورودی کار میکند و عملکرد بهتری با Pipeline ( که در ادامه توضیح دادهخواهد شده) دارد ارجح است. اگر ورژن قدیمیتری از Scikit-Learn را استفاده میکنید باید آن را از future_encoders.py بخوانید.
In [47]:
try:
from sklearn.preprocessing import OrdinalEncoder
except ImportError:
from future_encoders import OrdinalEncoder # Scikit-Learn < 0.20
با فراخوانی تابع $\tt{fit\underline{}transform}$ از این کلاس، داده دستهای ورودی به دادهی عددی کد میشود که ۱۰ خط اول آن را نمایش میدهیم. همچنین با استفاده از ويژگی $\tt{categories\underline{}}$ میتوان به رشتهی متنی دستهها پی برد.
In [48]:
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded[:10]
Out[48]:
In [49]:
ordinal_encoder.categories_
Out[49]:
مشاهده میکنیم که به جای هر کدام از مقادیر متنی ویژگی $\tt{ocean\_proximity}$ یکی از اعداد 0 تا 4 قرار داده شده است.
در واقع این نگاشت از متن به اعداد طبیعی را میتوانستیم به ترتیب دیگری انجام دهیم؛ مثلا به جای اینکه به $\tt{INLAND}$ مقدار 1 را نسبت دهیم میتوانستیم به آن مقدار 3 را نسبت دهیم.
همچنین میتوانستیم به جای اینکه مقادیر 0, 1, 3, 4 را نسبت دهیم، از مقادیر 0, 100, 300, 1000, 50000 استفاده کنیم. برای این که این کار را انجام دهیم میتوانیم از One-hot Encoding استفاده کنیم.
در این حالت مقادیر مختلفی که ویژگی های دستهای میگیرند از یکدیگر مستقل خواهند شد.
اگر مثلا یک ویژگی متنی داشته باشیم که 3 مقدار مختلف A, B, C را میگیرد آن را تبدیل به یک بردار 3 بعدی میکنیم به صورتی که:
A ---> [1, 0, 0]
B ---> [0, 1, 0]
C ---> [0, 0, 1]
B ---> [0, 1, 0]
C ---> [0, 0, 1]
In [50]:
try:
from sklearn.preprocessing import OrdinalEncoder # just to raise an ImportError if Scikit-Learn < 0.20
from sklearn.preprocessing import OneHotEncoder
except ImportError:
from future_encoders import OneHotEncoder # Scikit-Learn < 0.20
cat_encoder = OneHotEncoder(sparse=False)
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
Out[50]:
In [51]:
cat_encoder.categories_
Out[51]:
حال میخواهیم مراحل مختلف پیشپردازشی را که روی دادهها انجام دادیم (پر کردن Nanها و اضافه کردن ویژگی هایی مانند
$\tt{rooms\_per\_household}$ ) در قالب یک
Pipeline انجام دهیم
ابتدا ستونهایی را که مقادیرشان عددی است از ستونهایی که مقادیر غیرعددی دارند جدا میکنیم. چون که پیشپردازشی که روی این نوع ستونها باید انجام بگیرد متفاوت است.
In [52]:
numerical_columns = housing.columns.drop('ocean_proximity')
categorical_columns = pd.Index(['ocean_proximity'])
housing_numerical = housing[numerical_columns]
housing_categorical = housing[categorical_columns]
به صورت کلی عملکرد $\tt{Pipeline}$ به این صورت است که یک ورودی میگیرد و روی آن پردازشهایی انجام میدهد و سپس یک خروجی میدهد.
خطلولهای که ساختهایم از 3 مرحله تشکیل شده است.
مرحله اول $\tt{Imputer}$ است که جاهایی از داده ها را که Nan است پر میکند.
سپس خروجی مرحله اول وارد مرحله دوم میشود. کلاسِ مربوط به مرحله دوم را خودمان تعریف کردهایم.
این کلاس ویژگی های $\tt{rooms\_per\_household}$ و ... را به دادههایمان اضافه میکند. همچنین میتوانیم به عنوان ورودی تعیین کنیم که ویژگی $\tt{bedrooms\_per\_room}$ اضافه شود یا خیر.
آخرین مرحله از Pipeline که $\tt{StandardScaler}$ است مسئولیت نرمال کردن ستونهای عددی را برعهده دارد.
این تابع به صورت پیشفرض هر ستون را با یک تبدیل خطی به گونهای تغییر میدهد که میانگینش صفر شود و انحراف معیار آن برابر با ۱ شود.
In [53]:
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room=False): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
X_df = pd.DataFrame(X, columns=numerical_columns)
X_df["rooms_per_household"] = X_df["total_rooms"]/X_df["households"]
X_df["population_per_household"]=X_df["population"]/X_df["households"]
if self.add_bedrooms_per_room:
X_df["bedrooms_per_room"] = X_df["total_bedrooms"]/X_df["total_rooms"]
return X_df
numerical_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder(add_bedrooms_per_room=True)),
('std_scaler', StandardScaler()),
])
housing_numerical_transformed = numerical_pipeline.fit_transform(housing_numerical)
housing_numerical_transformed
Out[53]:
همانطور که مشاهده میکنیم میانگین ستونها عددهای بسیار نزدیک به صفر و انحراف معیار ستون ها ۱ است.
In [54]:
np.mean(housing_numerical_transformed, axis=0)
Out[54]:
In [55]:
np.std(housing_numerical_transformed, axis=0)
Out[55]:
حال با استفاده از کلاس $\tt{ColumnTransformer}$ میتوانیم تبدیلهای مختلفی روی ستونهای مختلف داده اولیه اعمال کنیم و در نهایت با کنار هم گذاشتن ستونهای تبدیل یافته به داده نهایی برسیم.
In [56]:
try:
from sklearn.compose import ColumnTransformer
except ImportError:
from future_encoders import ColumnTransformer # Scikit-Learn < 0.20
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
numerical_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder(add_bedrooms_per_room=True)),
('std_scaler', StandardScaler()),
])
categorical_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="most_frequent")),
("onehot_encoder", OneHotEncoder())
])
full_pipeline = ColumnTransformer([
("num", numerical_pipeline, numerical_columns),
("cat", categorical_pipeline, categorical_columns),
])
housing_prepared = full_pipeline.fit_transform(housing)
housing_prepared
Out[56]:
مشاهده میکنیم که داده نهایی آموزش 16512 سطر دارد و 16 ستون که ستونهایی از آن را چاپ میکنیم.
In [57]:
housing_prepared.shape
Out[57]:
In [58]:
housing.columns
Out[58]:
انتخاب یک مدل و آموزش دادن آن
حال وقت آن است که یک مدل انتخاب کرده و آن را با استفاده از دادههای آموزش تعلیم دهیم! به عنوان اولین مثال سعی میکنیم ویژگی $\tt{median\_house\_value}$ را برحسب سایر ویژگیها پیشبینی کنیم.
ساده ترین مدلی که برای تخمین زدن یک مقدار حقیقی بر حسب تعدادی ویژگی وجود دارد، رگرسیون خطی است. کتابخانه Scikit-learn تعداد زیادی از مدلهای یادگیری ماشین را به صورت آماده در خود جای داده است.
تکه کد زیر یک مدل رگرسیون خطی را تعریف میکند و سپس آن را به داده های آموزش میبرازاند(!) و بعد از برازش مدل میتوانیم با استفاده از تابع $\tt{score}$ درکی از میزان نزدیک بودن مقادیر تخمینی و مقادیر واقعی به دست بیاوریم.
برای رگرسیون خطی این امتیاز هرچقدر به 1 یا -1 نزدیک تر باشد به معنی این است که تخمین مدل به واقعیت نزدیکتر است.
حال وقت آن است که یک مدل انتخاب کرده و آن را با استفاده از دادههای آموزش تعلیم دهیم! به عنوان اولین مثال سعی میکنیم ویژگی $\tt{median\_house\_value}$ را برحسب سایر ویژگیها پیشبینی کنیم.
ساده ترین مدلی که برای تخمین زدن یک مقدار حقیقی بر حسب تعدادی ویژگی وجود دارد، رگرسیون خطی است. کتابخانه Scikit-learn تعداد زیادی از مدلهای یادگیری ماشین را به صورت آماده در خود جای داده است.
تکه کد زیر یک مدل رگرسیون خطی را تعریف میکند و سپس آن را به داده های آموزش میبرازاند(!) و بعد از برازش مدل میتوانیم با استفاده از تابع $\tt{score}$ درکی از میزان نزدیک بودن مقادیر تخمینی و مقادیر واقعی به دست بیاوریم.
برای رگرسیون خطی این امتیاز هرچقدر به 1 یا -1 نزدیک تر باشد به معنی این است که تخمین مدل به واقعیت نزدیکتر است.
In [59]:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
lin_reg.score(housing_prepared, housing_labels)
Out[59]:
حال میتوانیم با استفاده از مدلی که آموزش دادهایم مقدار $\tt{median\_house\_value}$ را برای 5 داده آموزش اول محاسبه کنیم و آنها را با مقادیر واقعی مقایسه کنیم.
In [60]:
# let's try the full preprocessing pipeline on a few training instances
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:", lin_reg.predict(some_data_prepared))
Compare against the actual values:
In [61]:
print("Labels:", list(some_labels))
یکی از معیار هایی که میتوان با آن میزان برازش مدل های رگرسیون را بررسی کرد، MSE یا میانگین مربعات خطاها است.
این معیار به این صورت محاسبه میشود که به ازای هرکدام از داده ها اختلاف تخمین مدل و مقدار واقعی را به توان دو میرسانیم و این مقادیر را میانگین میگیریم.
هرچقدر تخمین مدل بیشتر به واقعیت نزدیک باشد این مقدار کوچکتر خواهد بود.
برای اینکه Scale خطای حاصل با Scale مقدار هدف یکسان شود در آخر از آن جذر میگیریم.
این معیار به این صورت محاسبه میشود که به ازای هرکدام از داده ها اختلاف تخمین مدل و مقدار واقعی را به توان دو میرسانیم و این مقادیر را میانگین میگیریم.
هرچقدر تخمین مدل بیشتر به واقعیت نزدیک باشد این مقدار کوچکتر خواهد بود.
برای اینکه Scale خطای حاصل با Scale مقدار هدف یکسان شود در آخر از آن جذر میگیریم.
In [62]:
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse
Out[62]:
معیار دیگری که برای مقایسه وجود دارد MAE است.
مشکلی که MSE دارد این است که به دادههای پرت حساس است. یعنی اگر یکی از دادهها مقدار $\tt{median\_house\_value}$ اش به اشتباه عدد بسیار بزرگی وارد شده باشد، MSE مقدار بسیار زیادی میگیرد زیرا با توان 2 خطا رابطه دارد.
بجای استفاده از توان 2 میتوانیم از قدرمطلق استفاده کنیم و این مشکل را حل کنیم.
مشکلی که MSE دارد این است که به دادههای پرت حساس است. یعنی اگر یکی از دادهها مقدار $\tt{median\_house\_value}$ اش به اشتباه عدد بسیار بزرگی وارد شده باشد، MSE مقدار بسیار زیادی میگیرد زیرا با توان 2 خطا رابطه دارد.
بجای استفاده از توان 2 میتوانیم از قدرمطلق استفاده کنیم و این مشکل را حل کنیم.
In [63]:
from sklearn.metrics import mean_absolute_error
lin_mae = mean_absolute_error(housing_labels, housing_predictions)
lin_mae
Out[63]:
حال مدلی پیچیدهتر از رگرسیون خطی را به دادههای آموزش میبرازانیم!
مشاهده میکنیم که Score برابر با 1 شده است و MSE نیز برابر با صفر شده است!
در واقع این مدل مقدار $\tt{median\_house\_value}$ را به ازای تمام دادههای آموزش به صورت دقیق پیشبینی میکند آیا ما بهترین مدلی که میتوانستیم را پیدا کردهایم؟
مشاهده میکنیم که Score برابر با 1 شده است و MSE نیز برابر با صفر شده است!
در واقع این مدل مقدار $\tt{median\_house\_value}$ را به ازای تمام دادههای آموزش به صورت دقیق پیشبینی میکند آیا ما بهترین مدلی که میتوانستیم را پیدا کردهایم؟
In [64]:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
tree_reg.score(housing_prepared, housing_labels)
Out[64]:
In [65]:
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
Out[65]:
یافتن مدل مناسب
پیشتر دیدید که مدل $\tt{DecisionTreeRegressor}$ به صورت کاملا دقیق مقدار $\tt{median\_house\_value}$ را در دادههای هدف پیشبینی میکرد. اما همانطور که قبلتر گفته شد، این مدل ممکن است به دادههای آموزش بیش از حد برازیده باشد یا به اصطلاح Overfit شده باشد. برای اینکه متوجه شویم خطای واقعی این مدل رو دادهای که در هنگام آموزش با آن روبهرو نشده است تقریبا چقدر است، از Cross Validation استفاده میکنیم (دقت کنید که تا وقتی مدل نهایی خودمان را انتخاب نکردهایم نمیتوانیم از Test Set استفاده کنیم). تابع $\tt{cross\_val\_score}$ به این صورت عمل میکند که مثلا دادههای آموزش را به ۱۰ قسمت مساوی تقسیم میکند. سپس از ۹تا از این قسمتها برای آموزش مدل استفاده میکند و از یکی از این قسمتها برای ارزیابی مدل و محاسبه MSE. به این صورت با انتخاب هریک از ۱۰ قسمت به عنوان Validation Set و انتخاب ۹ قسمت دیگر به عنوان Train Set، ده امتیاز مختلف به دست میآوریم. میانگین این امتیازها میتواند معیار مناسبی از خطای مدل روی دادههایی که مشاهده نکرده است باشد.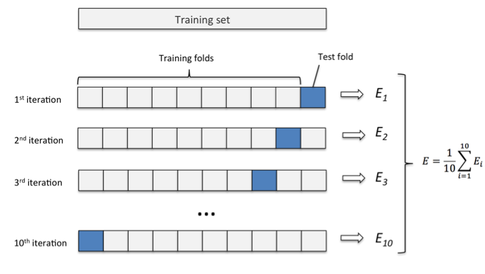 با مقایسه این مقادیر برای مدل $\tt{DecisionTreeRegressor}$ و $\tt{LinearRegressor}$ متوجه میشویم که با اینکه مدل رگرسیون درختی روی دادههای آموزش عملکرد بسیار خوبی دارد اما درواقع به آن دادهها Overfit شده است و روی دادههای جدید عملکرد مناسبی ندارد.
با مقایسه این مقادیر برای مدل $\tt{DecisionTreeRegressor}$ و $\tt{LinearRegressor}$ متوجه میشویم که با اینکه مدل رگرسیون درختی روی دادههای آموزش عملکرد بسیار خوبی دارد اما درواقع به آن دادهها Overfit شده است و روی دادههای جدید عملکرد مناسبی ندارد.
پیشتر دیدید که مدل $\tt{DecisionTreeRegressor}$ به صورت کاملا دقیق مقدار $\tt{median\_house\_value}$ را در دادههای هدف پیشبینی میکرد. اما همانطور که قبلتر گفته شد، این مدل ممکن است به دادههای آموزش بیش از حد برازیده باشد یا به اصطلاح Overfit شده باشد. برای اینکه متوجه شویم خطای واقعی این مدل رو دادهای که در هنگام آموزش با آن روبهرو نشده است تقریبا چقدر است، از Cross Validation استفاده میکنیم (دقت کنید که تا وقتی مدل نهایی خودمان را انتخاب نکردهایم نمیتوانیم از Test Set استفاده کنیم). تابع $\tt{cross\_val\_score}$ به این صورت عمل میکند که مثلا دادههای آموزش را به ۱۰ قسمت مساوی تقسیم میکند. سپس از ۹تا از این قسمتها برای آموزش مدل استفاده میکند و از یکی از این قسمتها برای ارزیابی مدل و محاسبه MSE. به این صورت با انتخاب هریک از ۱۰ قسمت به عنوان Validation Set و انتخاب ۹ قسمت دیگر به عنوان Train Set، ده امتیاز مختلف به دست میآوریم. میانگین این امتیازها میتواند معیار مناسبی از خطای مدل روی دادههایی که مشاهده نکرده است باشد.
با مقایسه این مقادیر برای مدل $\tt{DecisionTreeRegressor}$ و $\tt{LinearRegressor}$ متوجه میشویم که با اینکه مدل رگرسیون درختی روی دادههای آموزش عملکرد بسیار خوبی دارد اما درواقع به آن دادهها Overfit شده است و روی دادههای جدید عملکرد مناسبی ندارد.
In [66]:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
In [67]:
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)
In [68]:
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
برای این که مشکل Overfitting درخت رگرسیون را برطرف کنیم میتوانیم عمق آن را کم کنیم و یا از $\tt{RandomForestRegressor}$ استفاده کنیم.
این مدل از $\tt{n\_estimators}$ درخت رگرسیون استفاده میکند و نتایج آنها را به گونهای میانگین میگیرد.
با محاسبه Cross Validation Score مشاهده میکنیم که این مدل در مقایسه با دو مدل قبلی عملکرد بهتری دارد.
In [69]:
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=10, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
Out[69]:
In [70]:
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_rmse
Out[70]:
In [71]:
from sklearn.model_selection import cross_val_score
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
به جای استفاده از تابع $\tt{display\_scores}$ که خودمان تعریف کردیم، میتوانیم از کتابخانه Pandas استفاده کنیم که میانگین، انحراف معیار، کمینه ، بیشینه و چارک های یک سری عددی را حساب میکند.
In [72]:
scores = cross_val_score(lin_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10)
pd.Series(np.sqrt(-scores)).describe()
Out[72]:
فرض کنید که با بررسیهایی که انجام دادیم نتیجه گرفتیم که $\tt{RandomForestRegressor}$ مدل مناسبی است.
هر مدل تعدادی Hyperparameter دارد، برای مثال $\tt{n\_estimators}$ یکی از هایپرپارامترهای مدل $\tt{RandomForestRegressor}$ است.
با تغییر دادن این هایپرپارامترها نتیجههای متفاوتی به دست میآیند.
کتابخانه Scikit-learn توابعی فراهم کرده است که با آنها میتوان مقادیر مناسبی برای هایپرپارامترهای یک مدل پیدا کرد به طوری که خطای Cross Validation کمتر شود.
تابع $\tt{GridSearchCV}$ به این صورت عمل میکند که یک Grid از هایپرپارامترها را به عنوان ورودی میگیرد و روی تمام حالتهای مختلفی که وجود دارد $\tt{Cross\_val\_score}$ را محاسبه میکند.
پارامتر cv مشخص میکند که به ازای هر حالتِ مقداردهی برای هایپرپارامترها، برای محاسبه امتیاز با Cross Validation، از چند fold استفاده شود.
In [73]:
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# then try 6 (2×3) combinations with bootstrap set as False
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# train across 5 folds, that's a total of (12+6)*5=90 rounds of training
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error', return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
Out[73]:
حال میتوانیم بهترین هایپرپارامترهایی را که در جریان جستجو پیدا شدهاند را مشاهده کنیم.
In [74]:
grid_search.best_params_
Out[74]:
In [75]:
grid_search.best_estimator_
Out[75]:
کد زیر Cross Validation Score را به ازای هر کدام از حالت های مقداردهی هایپرپارامترها محاسبه میکند.
In [76]:
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
در جدول زیر اطلاعات کاملتری را میتوانیم مشاهده کنیم. اطلاعاتی مانند زمانی که طول میکشد تا هرکدام از مدل ها را آموزش دهیم، رتبه هرکدام از مدلها بر حسب Cross Val Score آنها، امتیاز هریک از مدلها روی fold های مختلف Cross Validation و ....
In [77]:
pd.DataFrame(grid_search.cv_results_)
Out[77]:
استفاده از $\tt{GridSearchCV}$ زمانی خوب است که بدانیم چه مقادیری برای هر هایپرپارامتر مناسب است.
در ابتدا ممکن است ایدهای از این که چه مقادیری برای هر هایپرپارامتر مناسب است نداشته باشیم. در این حالت میتوانیم از $\tt{RandomizedSearchCV}$ استفاده کنیم.
ورودی این تابع به جای این که یک Grid از هایپرپارامترهای مختلف باشد، یک توزیع احتمال برای هر هایپرپارامتر است.
این تابع به تعداد $\tt{n\_iters}$ از این توزیعهای احتمال نمونه تصادفی میگیرد و سپس Cross Val Score را برای هرکدام از این حالتهای مقداردهی محاسبه میکند.
در واقع بهترین روشی که برای انتخاب هایپرپارامتر وجود دارد این است که ابتدا از $\tt{RandomizedSearchCV}$ استفاده کنیم و بعد از این که فهمیدیم چه بازهای از هر هایپرپارامتر مناسب است، از $\tt{GridSearchCV}$ استفاده کنیم تا به به صورت دقیقتر جستجو کنیم و مقدار مناسب را برای هر هایپرپارامتر به دست آوریم.
In [78]:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
Out[78]:
In [79]:
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
برای این مدل نیز میتوانیم بهترین هایپرپارامترهایی را که در جریان جستجو پیدا شدهاند را مشاهده کنیم.
In [80]:
rnd_search.best_params_
Out[80]:
برای داشتن شهود بهتر نسبت به آن که متغیرهای مدل ما چگونه روی پیشبینی نهایی تاثیر دارند، میتوان از ویژگی $\tt{feature\underline{}importances\underline{}}$ استفاده کرد. برای مدل $\tt{RandomForestRegressor}$ای که با GridSearch به دست آوردیم اهمیت متغیرها را بررسی میکنیم.
In [81]:
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
Out[81]:
برای بهتر فهمیدن اعداد بالا هر کدام را در کنار متغیر مربوطهاش قرار میدهیم:
In [82]:
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_encoder = full_pipeline.named_transformers_["cat"].named_steps['onehot_encoder']
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)
Out[82]:
حال با استفاده از بهترین مدلی که به دست آوردیم روی داده تست (پس از آمادهسازی آن) پیشبینی انجام میدهیم و میزان خطا را چاپ میکنیم.
In [83]:
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
In [84]:
final_rmse
Out[84]:
می توان خطلوله مربوط به بخش آمادهسازی داده را با خطلوله مربوط به مدل رگرسیون خطی در یک Pipeline قرار داد.
In [85]:
full_pipeline_with_predictor = Pipeline([
("preparation", full_pipeline),
("linear", LinearRegression())
])
full_pipeline_with_predictor.fit(housing, housing_labels)
full_pipeline_with_predictor.predict(some_data)
Out[85]:
یک نکته بسیار کاربردی ذخیره کردن مدل برای استفاده از آن در آینده است. برای این کار میتوان مدل خود را در فایلی با پسوند .pkl با استفاده از تابع $\tt{dump}$ ذخیره کرد و همان فایل با تابع $\tt{load}$ قابل بارگیری است.
In [86]:
my_model = full_pipeline_with_predictor
In [87]:
from sklearn.externals import joblib
joblib.dump(my_model, "my_model.pkl") # DIFF
#...
my_model_loaded = joblib.load("my_model.pkl") # DIFF
همان طور که در بالا ذکر شد میتوان هایپرپارامترهای مدل را با استفاده از توزیعهای مختلفی در روش $\tt{RandomizedSearchCV}$ مقداردهی کرد. به عنوان مثال از دو توزیع نمایی و هندسی با استفاده از کتابخانه scipy به صورت زیر میتوان نمونهبرداری کرد.
In [88]:
from scipy.stats import geom, expon
geom_distrib=geom(0.5).rvs(10000, random_state=42)
expon_distrib=expon(scale=1).rvs(10000, random_state=42)
plt.hist(geom_distrib, bins=50)
plt.show()
plt.hist(expon_distrib, bins=50)
plt.show()

